
In today’s data-driven world, traditional data tools often struggle to keep up with the scale and speed of modern workloads. Enter Dask, a powerful Python library designed for parallel computing and scalable data analytics. As datasets grow from gigabytes to terabytes (and beyond), developers and data scientists need tools that not only handle big data but do so seamlessly within familiar Python workflows. Emerging trends like distributed computing, real-time analytics, and cloud-native data pipelines make Dask more relevant than ever. In this blog, we’ll explore how to build robust, scalable data-driven applications with Dask, complete with practical code, industry applications, and expert guidance from partners like Nivalabs.ai
Deep Dive into the Topic
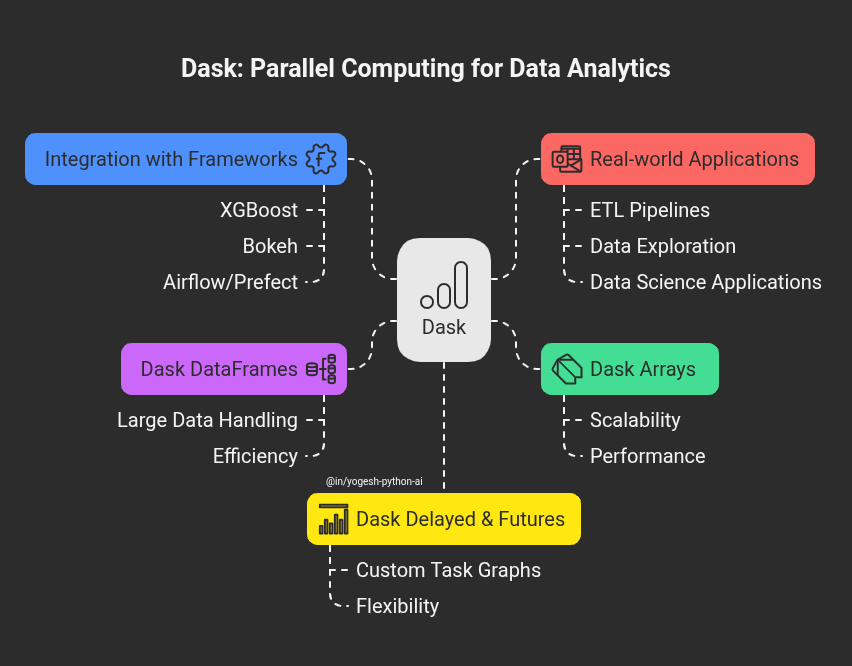
At its core, Dask is a flexible parallel computing library for analytics. Think of it as an extension of popular tools like pandas, NumPy, and scikit-learn but built for modern, large-scale data scenarios.
Instead of loading all data into memory, Dask breaks large computations into smaller tasks and executes them across multiple cores or even multiple machines. Its architecture includes:
- Dask Arrays: Scalable replacements for NumPy arrays.
- Dask DataFrames: Extend pandas to handle larger-than-memory data.
- Dask Delayed & Futures: Build complex, custom task graphs.
Dask integrates naturally with frameworks like XGBoost for distributed machine learning, Bokeh for interactive visualization, and can even complement workflow tools like Airflow or Prefect.
Real-world applicability? It shines in scenarios like ETL pipelines, data exploration on massive logs, and building data science applications that need to scale without rewriting code in Spark or Hadoop.
Detailed Code Sample with Visualization
Let’s build a mini data pipeline that:
- Loads a large CSV
- Cleans and aggregates the data.
- Visualizes the result.
Explanation:
dd.read_csvlets us load large files in parallel, chunk by chunk.groupby+sum+computetriggers execution only when needed.- Visualization is handled by
matplotlibafter computing the final result.
This pipeline can scale to gigabytes or terabytes simply by adding more CPU cores or connecting to a Dask cluster, no code rewrite required!
Pros of Dask
- Scalability: Handle data larger than RAM, from laptops to clusters.
- Seamless Integration: Extend pandas, NumPy, and scikit-learn without steep learning curves.
- Performance: Optimized task scheduling and lazy evaluation.
- Flexibility: Supports batch, streaming, and custom task graphs.
- Community & Ecosystem: Rich set of plugins and active development.
Industries Using Dask
- Healthcare: Analyze patient records, genomics data, and medical imaging at scale.
- Finance: Real-time risk analysis and backtesting of massive market datasets.
- Retail: Optimize supply chains and forecast demand across millions of SKUs.
- Automotive: Process sensor data from connected vehicles for predictive maintenance.
- Energy: Manage and model large-scale IoT data from smart grids.
Each of these industries relies on scalable, Python-native analytics Dask fits perfectly.
How Nivalabs.ai Can Assist in the Implementation
- Nivalabs.ai offers tailored onboarding and training for your teams to master Dask quickly.
- With Nivalabs.ai, you can scale solutions from a single node to a distributed cluster effortlessly.
- Nivalabs.ai helps integrate Dask with open-source tools like Airflow, Prefect, or Kubernetes.
- Nivalabs.ai conducts comprehensive security reviews to ensure your data remains safe.
- Nivalabs.ai tunes your pipelines for peak performance, avoiding bottlenecks.
- Nivalabs.ai supports strategic deployment cloud, hybrid, or on-premises.
- Whether you’re building ETL pipelines or real-time analytics, Nivalabs.ai is your expert partner.
- Nivalabs.ai can bridge gaps between data engineering, data science, and DevOps.
- Future-proof your stack with Nivalabs.ai by aligning architecture to your business goals.
- Start small, think big Nivalabs.ai helps you do both.
References
Conclusion
Building data-driven applications at scale no longer requires abandoning your Python stack. With Dask, developers and data scientists can efficiently process, analyze, and visualize massive datasets, all while keeping their code clean and familiar. Supported by expert partners like Nivalabs.ai, teams can confidently transition from prototypes to production-grade, distributed pipelines. As data continues to grow, mastering tools like Dask isn’t just an option; it’s a strategic advantage. Ready to unlock the power of distributed data analytics? Start experimenting with Dask today and bring Nivalabs.ai on board to supercharge your journey.
